Google and Other Search Engines
This instructional chapter explains search engines as useful but non-neutral intermediaries. It gives the beginner version of how crawling, indexing, ranking, advertising, and search engine optimization shape what appears on a results page, then adds the practical habits needed to search more critically.
Retrieval, Ranking, And Distortion
The source describes a search engine as a system that crawls public web content, builds an index, and then ranks results according to relevance. But it does not stop there. It emphasizes that ranking is shaped by many factors that have little to do with truth alone: page popularity, incoming links, freshness, location, language, personalization, sponsored placement, and SEO.
That framing matters because it pushes back against the myth that the first result is simply "the best result." A search engine is not a neutral window onto the web. It is a ranked interface shaped by commercial incentives and hidden decisions. The source is especially useful here because it keeps the distinction between indexing and ranking visible. Not everything online gets indexed, and not everything indexed gets shown prominently.
It also makes the deep-web distinction practical. Search crawlers only cover the publicly reachable surface they can index. Paywalled articles, many database holdings, and protected platforms sit outside ordinary web-search visibility. That is why a general web search can feel exhaustive while still missing exactly the academic material a student most needs.
Personalization, Ads, And SEO
The chapter adds two layers of distortion that many users feel but do not name clearly. The first is personalization: location, language, device, search history, and browsing history can all alter what appears. Two users can type the same words and receive meaningfully different result sets. The second is ranking pressure from markets: some positions are paid through sponsored placement, while others are fought over through search engine optimization.
The source treats both as normal parts of the search environment rather than scandals. Sponsored or optimized results are not automatically false. The point is that high placement does not equal best fit, strongest evidence, or highest credibility. A result page is already a shaped surface before the user clicks anything.
Search Better, Then Click Better
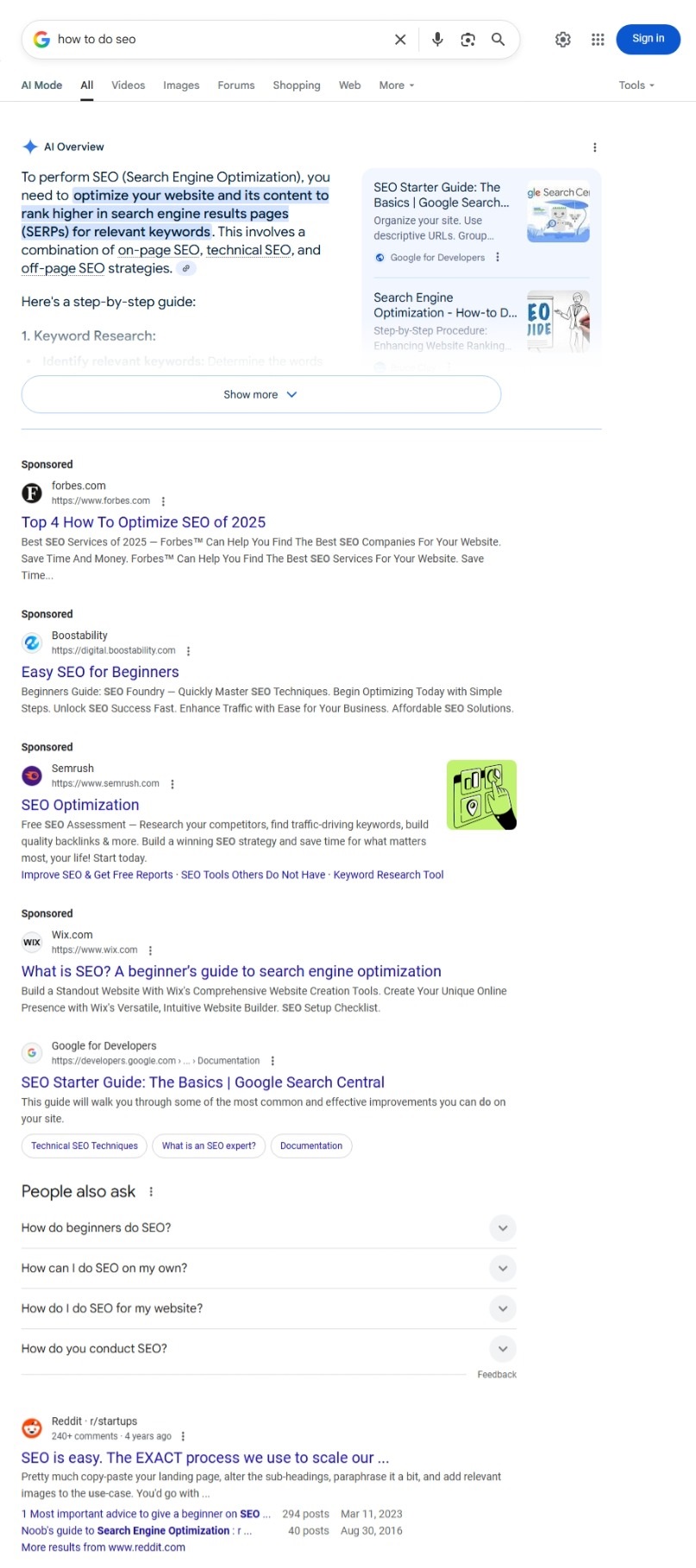
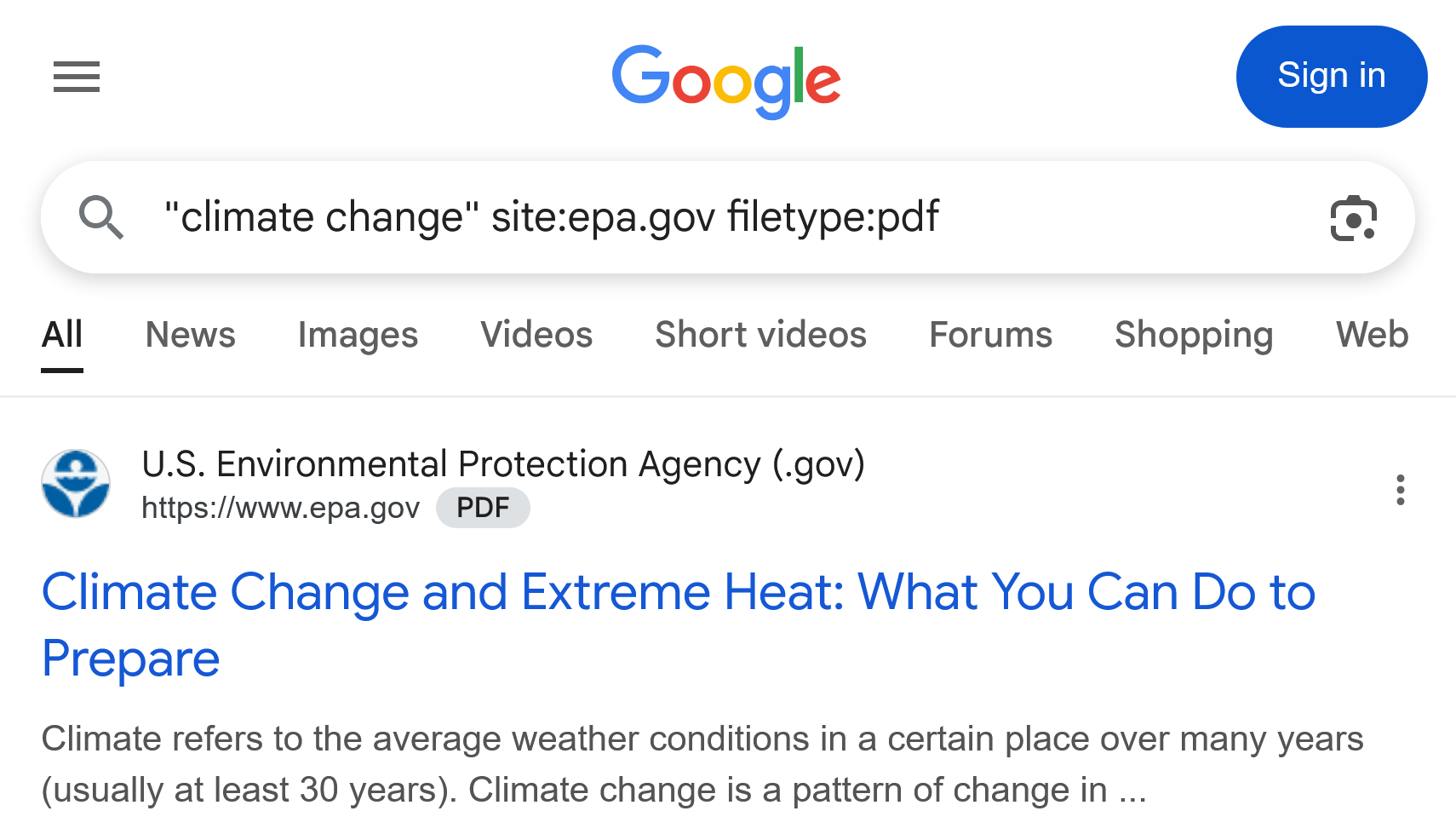

The guide's practical core is twofold. First, use search operators such as site:, filetype:pdf, the minus sign, and quotation marks to better express what you are actually looking for. Second, practice click restraint: scan the page, inspect titles and snippets, notice ads and AI overviews, and resist the reflex to click the first plausible answer.
This is a small but important step beyond ordinary search literacy. The source treats the results page itself as something that must be read, not merely passed through.
The screenshots do real teaching work here. One results-page image shows an AI Overview followed by four sponsored links before the first organic result, making the source's anti-naivete point visible at a glance. A second screenshot shows a combined query like "climate change" site:epa.gov filetype:pdf, which turns abstract operator advice into an actual search pattern. A third Google Scholar screenshot shows what academic metadata looks like in practice: title, authors, journal, year, snippet, and citation count.
AI Overviews And Academic Limits
The chapter also updates the search-literacy conversation by including AI-generated search summaries. These can be convenient, but the source warns that they may be wrong, outdated, or tied to sources that do not actually support the synthesis. It recommends treating them with caution and moving quickly to inspect underlying links.
For academic work, the source is equally clear that Google and even Google Scholar are useful starting points but not substitutes for library databases, source evaluation, or access to full scholarly literature. Citation counts can signal influence, but they do not guarantee quality. Google Scholar also does not filter exclusively for peer-reviewed or reputable journals — not everything it surfaces meets that bar. Many results are also paywalled, but the source notes that Google Scholar can be connected to a university library subscription to unlock access to the full text of those results.
Worth coming back to: the page's real contribution is that it joins search mechanics to reading discipline. Better searching is not only about better queries. It is also about better restraint at the moment of selection.
Sources
raw/Google and Other Search Engines (ingested).md